
{kind=link}
Background
Recently I listened to a lecture by Xu Hao(徐昊) about how to train ChatGPT to become a domain expert so we can use it to solve various problems in that domain.
The most impressive part of the whole lecture was the training method. It trains ChatGPT by having it ask us questions, and then we give answers. This is completely opposite to my daily use of ChatGPT.
Training method
Step 1: Enter known requirements
We need to enter the currently known requirements into ChatGPT. When we need someone else to complete a task, the first thing to do is introduce the basic situation of the task.
Step 2: Let ChatGPT ask questions
After entering the known requirements, we need to confirm ChatGPT understands the requirements. The most important thing is to let ChatGPT ask questions when it does not understand the requirements. This is like always asking, “Any questions?” after introducing the basic situation of a task.
This is the most critical step. ChatGPT’s questions can help us find omissions in the known requirements, which can often lead us to think more deeply.
Step 3: Answer questions and have ChatGPT ask us questions again
After ChatGPT asks questions, we first provide answers and then return to step 2 to see if ChatGPT has any other questions. This is like always asking, “Any other questions?” after answering someone else’s questions.
Step 4: Repeat the above steps until ChatGPT has no questions
Continuously repeat steps 2 and 3 until ChatGPT has no questions. This is a process from diffusion to convergence. Initially there will be many questions, but as more information is entered, the number of questions will decrease.
Step 5: Output complete requirements
When ChatGPT has no questions, we can ask it to output a complete set of requirements that it understands. These requirements are our domain model. After entering the model, ChatGPT can more accurately solve problems in that domain.
Example
Based on the above training method, I had ChatGPT help me complete the requirements for a crawler program.
Known requirements
In the known requirements, I described the architecture, technology stack and business logic.
After the requirement description was completed, I asked ChatGPT to ask questions when it did not understand or needed clarification.

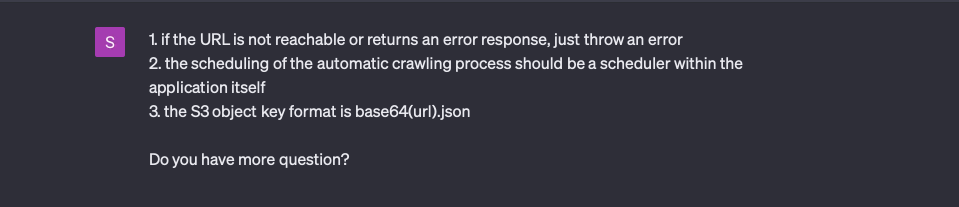
First round of questions
In the first round, ChatGPT asked three questions:

I did not consider the third question. This was the first omission ChatGPT found.
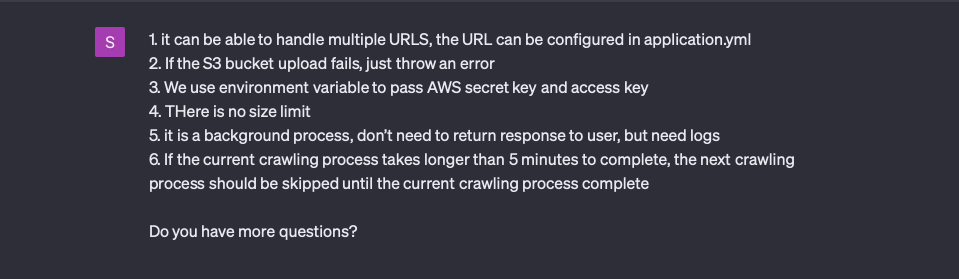
Second round of questions
In the second round, ChatGPT asked six questions:

I did not consider the fourth and sixth questions. This time ChatGPT helped me find two omissions.
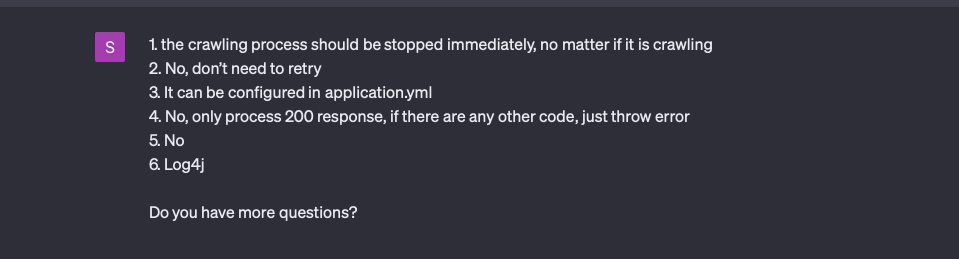
Third round of questions
In the third round, ChatGPT asked six questions:

I did not consider the first, second and fourth questions. This time ChatGPT helped me find three omissions.
Fourth round of questions
In the fourth round, ChatGPT asked six questions:
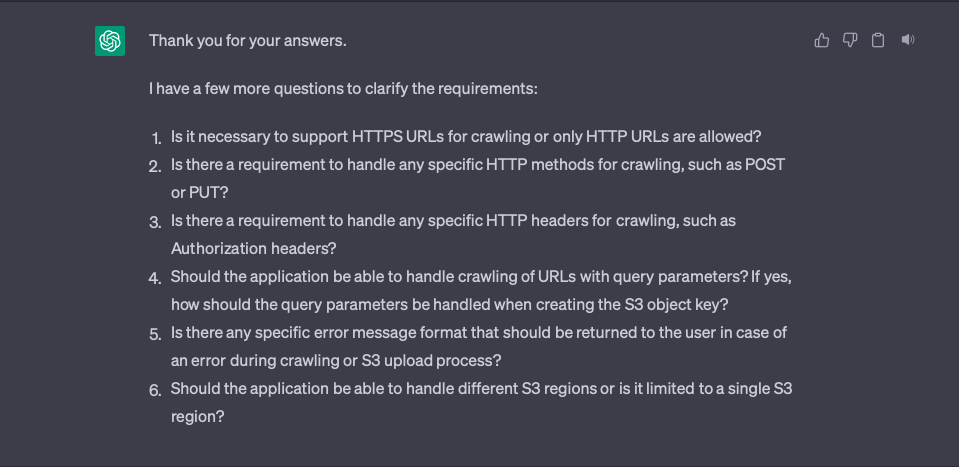
I did not consider the first, second, third and fourth questions. This time ChatGPT helped me find four omissions.
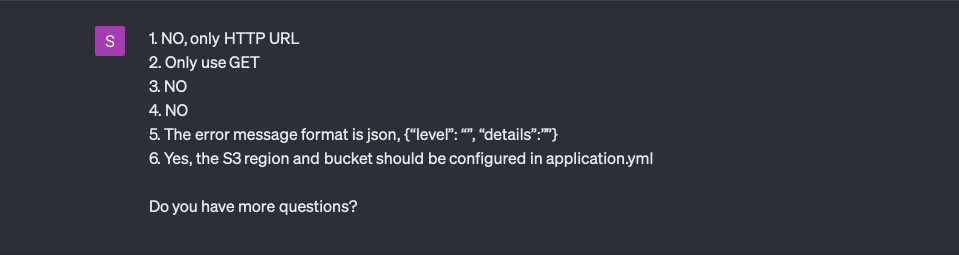
Fifth round of questions
In the fifth round, ChatGPT only asked one question:
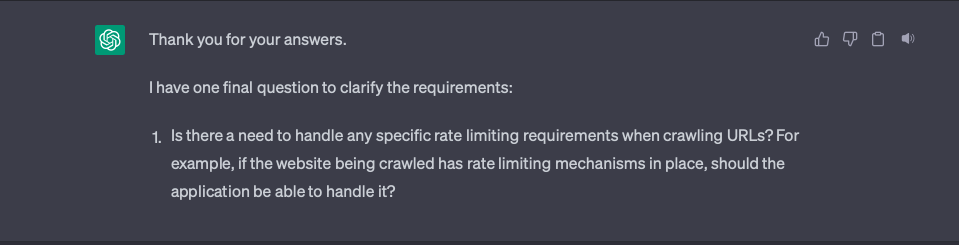
I had considered this question but did not write it in the known requirements.

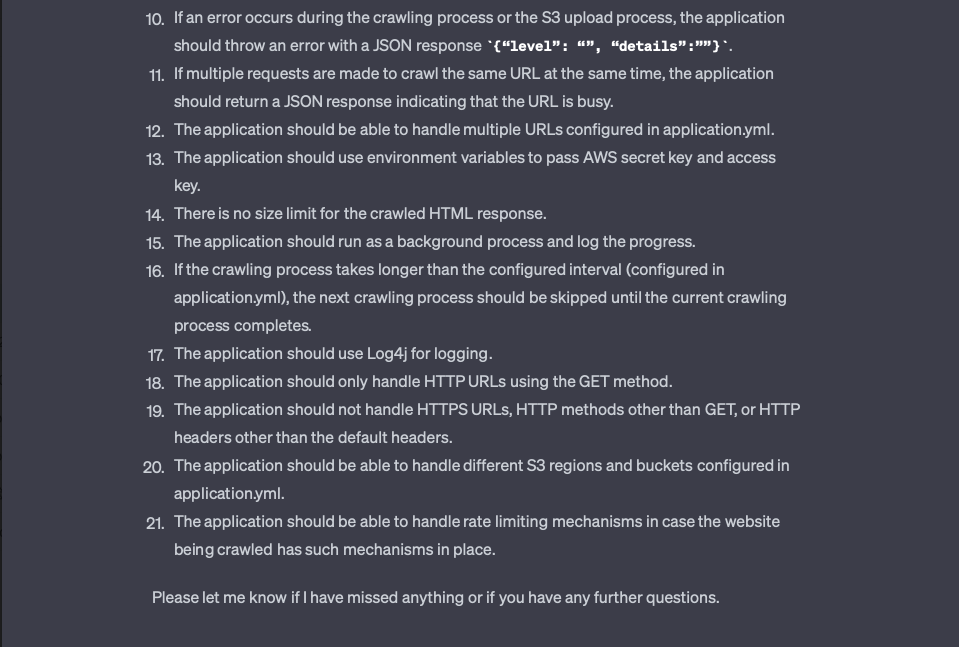
Complete requirements
After no questions, ChatGPT output the complete requirements it understood.

Summary
When I first heard of this training method, I didn’t really believe that ChatGPT’s questions could converge, but the facts speak for themselves. It can not only converge but also find very important omissions to make the requirements more complete.
Comments