
{kind=link}
Introduction
In the article “How to Get the Team to Truly Embrace AI Coding Assistants?”, I explored in detail how to improve GitHub Copilot’s behavior by designing system instructions to enhance user trust. Recently, to help my child learn typing, I decided to develop a typing practice website to validate the effectiveness of the system instructions mentioned in the article.
Showcase
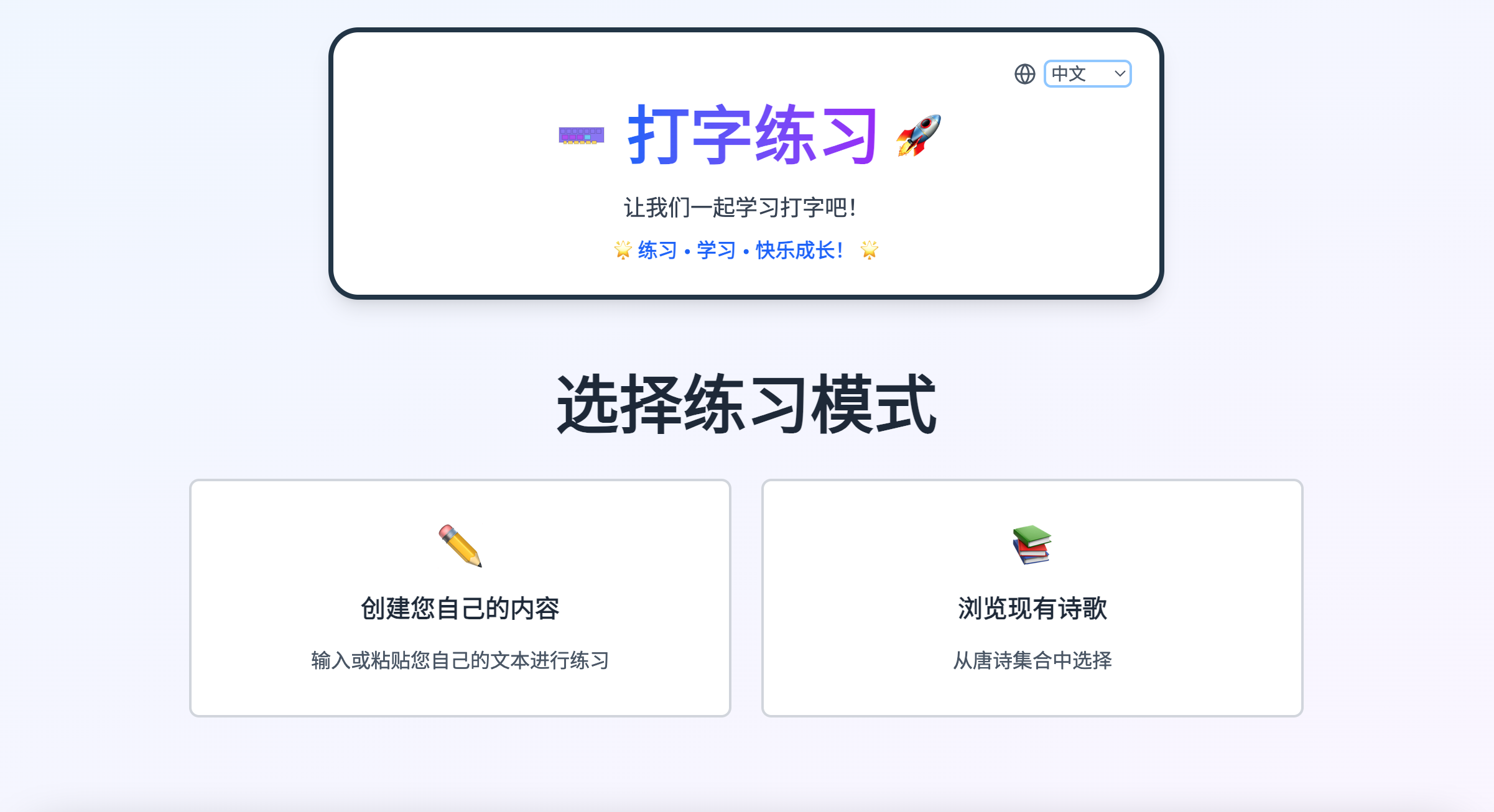
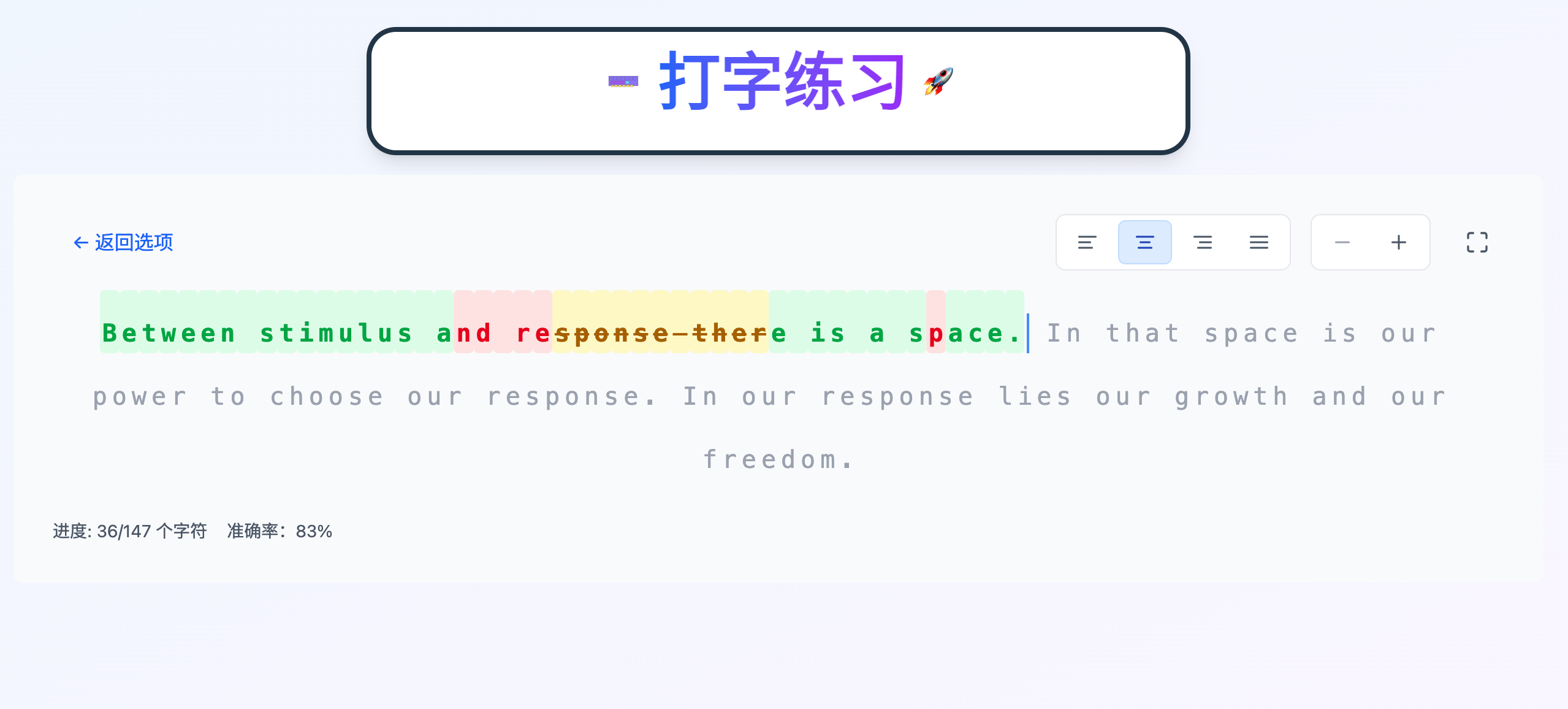
The project’s source code is hosted on https://github.com/sjmyuan/typing-practice, and the website has been deployed to https://typing.shangjiaming.com/. Currently, the site supports the following features:
- Custom Content Practice: Users can input any text for typing practice.
- 300 Tang Poems Practice: Built-in classic Tang poetry content, ideal for Chinese learners.
- Multilingual Support: Practice content can be in Chinese Pinyin or English.
Here are some screenshots of the website interface:

Development Process
Throughout the development process, I added the following content to GitHub Copilot’s system instructions:
- Knowledge (Knowledge): Including project description, tech stack, coding guidelines, and other foundational information.
- Skills (Skills): Such as requirement clarification, solution planning, Test-Driven Development (TDD), and other key capabilities.
- Rules (Rules): Defined specific requirements for the development process, such as:
- After users submit requirements, clarify them first, then plan solutions, and finally implement using TDD.
- Run tests after modifying code or tests.
- Use files to store and retrieve command-line outputs.
- Update Storybook documentation.
- Adhere to the Open-Closed Principle.
All code was generated by GitHub Copilot, and I only provided necessary inputs. A typical feature development process looks like this:
- Add Back to Options button.
- Add Fullscreen button.
The information I provide throughout the development process can be divided into the following categories:
- New Feature Requests: Describe the new functionality to be implemented.
- Existing Feature Modifications: Specify adjustments needed for existing features.
- Bug Descriptions: Point out observed issues.
- Test Fixes: Describe failed test cases and let GitHub Copilot fix them (usually due to previous sessions not running all tests).
- Test Result Feedback: Provide test results or error messages, especially when GitHub Copilot cannot read command-line outputs.
- Implementation Hints: When dissatisfied with GitHub Copilot’s implementation, provide reusable code, existing similar functions, or missing code hints.
- Refactoring Requests: Suggest refactoring for overly complex logic or large modules in the generated code.
Among these, existing feature modifications were the most common. As more features were added, I found that many details were missing from the user stories prepared earlier, but I didn’t want to spend too much time filling in those details (mainly due to laziness). Therefore, when providing information to GitHub Copilot, I often could only describe simple details and then iteratively request modifications based on its generated results until the overall functionality met expectations.
Additionally, when dealing with global changes (such as supporting internationalization), test fixes and implementation hints appeared more frequently. This is because GitHub Copilot tends to focus on context, concentrating modifications on the modules mentioned in the requirements while ignoring tests for other modules, causing pipeline failures.
Development Experience
During the development process, Claude Sonnet 4 provided the best experience. It was able to understand and execute the system instructions I set up well.
Sometimes, GitHub Copilot + Claude Sonnet 4 brought pleasant surprises. For example, when fixing bugs, it would clearly tell me that the current implementation matched the expected behavior and pointed out that my bug description might be incorrect, subsequently offering two solutions for me to confirm which one aligned better with expectations. When it couldn’t locate issues through code analysis, it even automatically generated tests or added logs to help pinpoint causes. However, this sometimes caused a minor issue: GitHub Copilot occasionally forgot to clean up previously debugged files or code.
Initially, I carefully reviewed the generated code, especially the test code. But as development progressed, I gradually reduced the frequency of code reviews, and sometimes I couldn’t fully understand the generated code. I became increasingly accustomed to focusing only on the clarified requirements and generated solutions provided by GitHub Copilot, clicking the run button when necessary. This might be what is referred to as Vibe Coding. I’m unsure if this mode is good or bad, but under the following circumstances, I might become more cautious:
- Code Will Be Reviewed by Others: In this case, I would ensure I understand all the code and guarantee it aligns with the team’s best practices.
- Code Will Be Tested by Others: Here, I would at least carefully review test cases to ensure they verify correct behaviors. Additionally, I would provide more details when submitting tasks to GitHub Copilot.
- Time-Constrained Tasks: To avoid wasting time interacting with GitHub Copilot, I would directly modify its generated code to quickly complete implementations.
Initially, I linked architecture documents and coding guidelines to the system instructions, thinking it would improve the quality of the generated code. However, the results were counterproductive:
- Distraction: Large amounts of architectural and coding guideline information distracted GitHub Copilot, reducing its compliance and execution quality of system instructions.
- Outdated Content Impact: These documents were prepared before coding, and as the code evolved, some parts became outdated. Since I didn’t update them promptly, GitHub Copilot generated incorrect code based on outdated content. I tried letting it update the documents after implementing features, but it seemed to fall into a “chicken-and-egg” problem, with unsatisfactory results.
Therefore, in the later stages of development, I removed the architecture and coding guideline content, adding necessary information only when GitHub Copilot made obvious errors to prevent similar issues from recurring.
Additionally, I noticed an interesting phenomenon: when test cases failed, GitHub Copilot tended to modify the implementation code rather than the tests themselves. This aligns with TDD principles, as we should indeed improve implementations based on tests. However, sometimes I needed to modify tests to reflect new requirements. For instance, in the last session, GitHub Copilot modified the implementation code but missed updating some tests. At such times, I needed to explicitly state that tests should be modified according to the implementation rather than just reporting a failed test case.
Conclusion
By equipping GitHub Copilot with advanced models and designing effective system instructions, we can achieve a Vibe Coding experience somewhat similar to Cursor. This mode can generate software that meets about 60% of our needs, but raising the quality to 95% or higher may not be achievable through vibe coding alone. The key to success often lies in the details that elevate quality from 60% to 95%.
For example, generating a functional webpage with GitHub Copilot isn’t difficult, but requiring it to generate a page that meets pixel-level design specifications demands more complex instructions, potentially exceeding its capabilities. After all, whether we can accurately describe all pixel-level requirements is questionable; even if we could, how much of it can GitHub Copilot understand and comply with?
In this small project, I more often felt like a developer continuously accepting results generated by GitHub Copilot according to its standards, rather than making it produce results entirely according to mine. The former made me comfortable—I just provided simple clues and accepted results that looked decent enough. The latter, however, was painful: I had to design everything in advance, reject results that didn’t meet expectations, repeatedly provide feedback, and possibly get stuck in an ineffective feedback loop.
However, in real projects, most situations require GitHub Copilot to produce results according to our standards. Therefore, we still need to continuously optimize its behavior based on the Trust Enhancement Model to gradually increase our trust in it.
Comments