
{kind=link}
Has your team enabled AI coding assistants? Have you been urged daily to increase usage rates? Have you noticed that, many times, team members do not use AI coding assistants to write code? Besides conventional knowledge sharing and use cases sharing, are there any other effective methods to boost usage?
Since my team enabled GitHub Copilot three months ago, these issues have been bothering me, and this article is my attempt at finding answers.
Why Increase the Usage Rate of AI Coding Assistants?
Before discussing “how”, we must first clarify “why.”
Personally, I believe it’s based on a core assumption: using AI coding assistants can enhance development efficiency, and the more they are used, the greater the efficiency improvement. Let’s temporarily accept this assumption as valid and verify it through practice.
So, can we mandate that team members use AI coding assistants in all their work? Given the unproven assumption, such actions carry significant risks—what if it doesn’t improve efficiency? What if it’s not true that “the more it’s used, the higher the efficiency?” As discussed in How to handle unknown problems?, the key to handling such situations lies in reducing potential losses, with the best approach being granting developers autonomy—let them decide when and in what scenarios to use AI coding assistants.
In cases where developers have the freedom to choose whether or not to use AI coding assistants, will usage naturally increase? From our team’s experience using GitHub Copilot for three months, developers tend to use it frequently in the following scenarios:
- Code comprehension
- Solution analysis
- Function-level code refactoring
- Function-level algorithm implementation
- Unit test generation
And rarely in these scenarios:
- Line-level code modifications
- Modifications achievable with IDE shortcuts
- Bug fixes
- Complex task implementations (especially those spanning multiple files or modules)
If left without external intervention, the team’s usage pattern will stabilize in this state.
So, what actions should we take to increase usage? That’s what we’ll discuss next.
Usage Rate Model for AI Coding Assistants
Here’s an analogy: an AI coding assistant is like an automation tool, capable of completing tasks assigned by developers. The field of human-computer interaction has numerous studies on automation tools, and I found the model in Trust, self-confidence, and operators’ adaptation to automation particularly suitable for explaining the usage rate of AI coding assistants:
\[Usage\text{ }Rate = \frac{100}{e^{-s \times (Trust - Self\text{ }Confidence - b)}}\]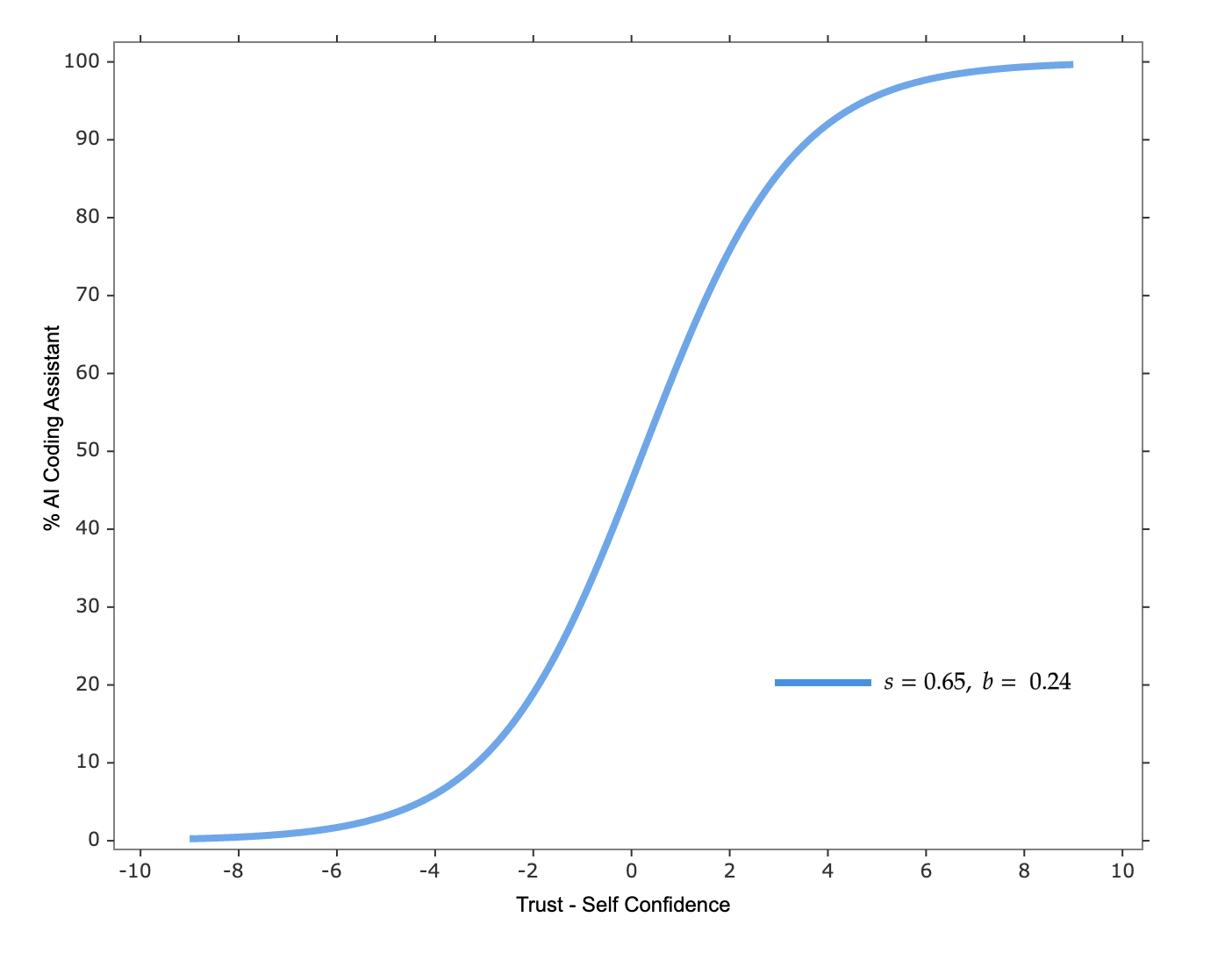
Here, we define the \(Usage\text{ }Rate\) as the percentage of time developers use AI coding assistants out of their total development time. From the model, we see that factors affecting usage rates include four elements:
- \(Trust\): Developers’ level of trust in AI coding assistants, which can be rated from 1-10 based on subjective perception.
- \(Self\text{ } Confidence\): Developers’ confidence in their own abilities, which can also be rated from 1-10.
- Bias (\(b\)): Developers’ inherent negative tendency towards AI coding assistants, mainly determined by past experiences and environment. A higher \(b\) value means lower willingness to use AI coding assistants.
- Shape parameter (\(s\)): The strength of developers’ inclination to maintain existing work habits. Larger \(s\) values indicate greater resistance to changing current development habits.
It’s important to note that an AI coding assistant is not a single-function automation tool like a shortcut key but a general automation tool capable of handling any programming task. Therefore, for the same AI coding assistant, model parameters (\(Trust\), \(Self\text{ }Confidence\), \(b\), \(s\)) vary across different task types. For example:
- Although developers trust AI coding assistants to generate code blocks efficiently, this does not mean they equally trust them to fix online bugs effectively.
- While developers are confident in implementing new features efficiently within existing structures, it does not mean they also trust themselves to refactor architectures efficiently.
- Even though developers are eager to try various uses of AI coding assistants in personal projects, it does not mean they are equally willing to take time and risk in commercial projects to explore various uses of AI coding assistants.
- With increased trust and reduced bias, the usage rate increases differently for code block generation compared to simple refactorings (ones that can be done with shortcuts).
Given varying model parameters for each task, and since it’s difficult to list all possible tasks, how is this model useful? I think it serves at least three purposes:
First, it helps us break down goals. We’ve been aiming to increase the overall usage rate of AI coding assistants, and this model tells us that this goal can be further broken down into several sub-goals: increasing usage in various task scenarios. If we focus solely on the end goal, we will inevitably adopt generic measures, leading to stagnation. Only by breaking down the ultimate goal into sub-goals, and then adopting general measures alongside targeted ones for different sub-goals, can we drive progress in achieving both sub-goals and the ultimate goal.
Second, it tells us what to do. This model reveals factors influencing the usage rate of AI coding assistants, and our task is to take measures to change these factors.
Lastly, it helps explain some phenomena, allowing us to understand the causes behind them and avoid incorrect actions.
Let’s use this model to explain some common phenomena.
Explanations of Common Phenomena with the Model
Why do junior developers use AI coding assistant more than senior developers?
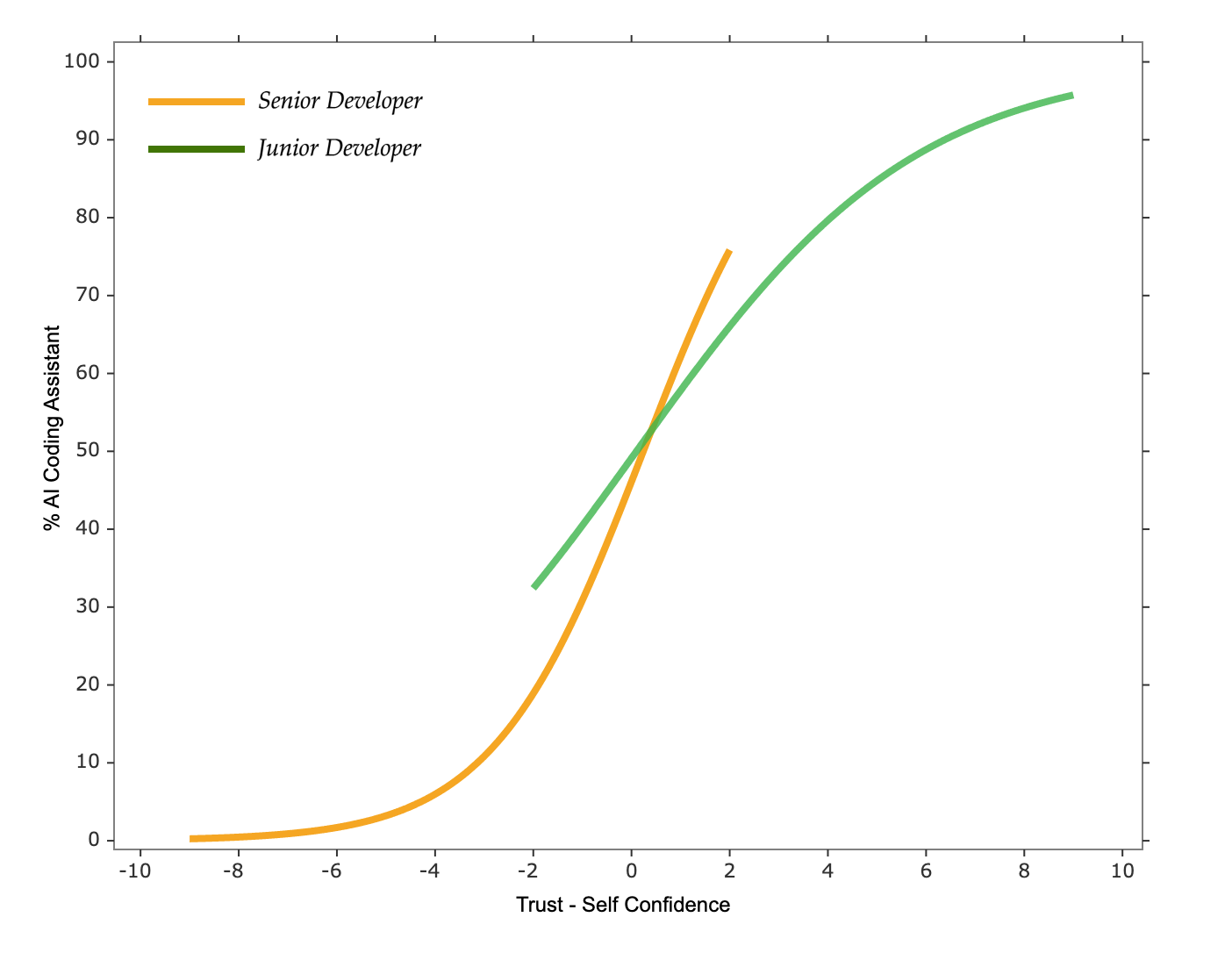
Within the same team, for similar tasks, everyone’s trust level in AI coding assistants should be relatively close. There may be differences in biases towards AI coding assistants, but they shouldn’t be too large.
The possible difference is that junior developers often have lower self-confidence compared to senior developers, which is reflected in the model as a larger \(Trust - Self\text{ }Confidence\) value, leading to higher usage rates among junior developers.
Why is AI coding assistant used more in unfamiliar domains than familiar ones?
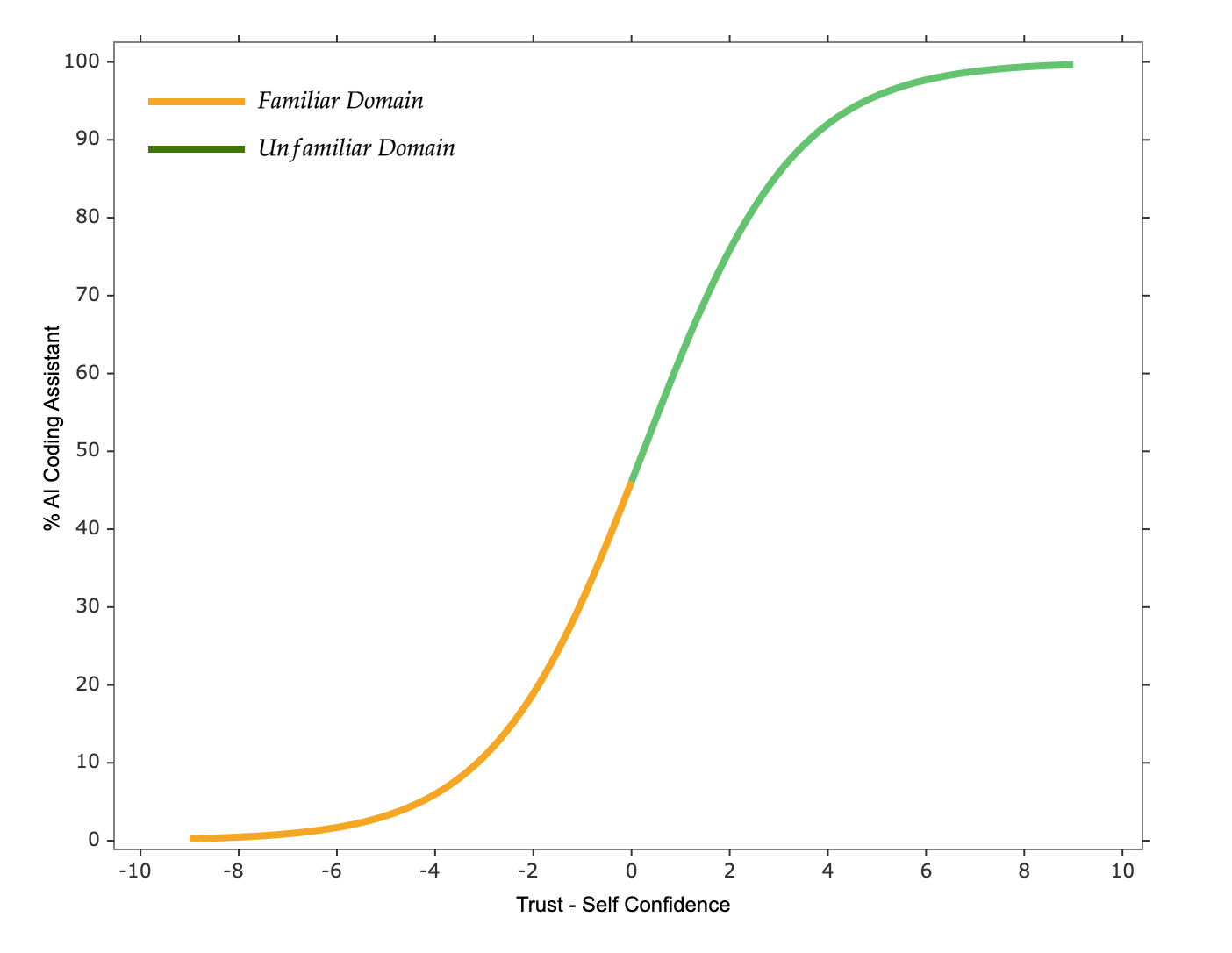
For the same developer, facing similar tasks over short periods, their bias and trust levels toward AI coding assistants won’t fluctuate significantly. However, when dealing with unfamiliar domains, their self-confidence is usually lower compared to familiar domains, resulting in a higher \(Trust - Self\text{ }Confidence\) value, leading to higher usage rates in unfamiliar domains.
Why is AI coding assistant used more in personal projects than in commercial projects?
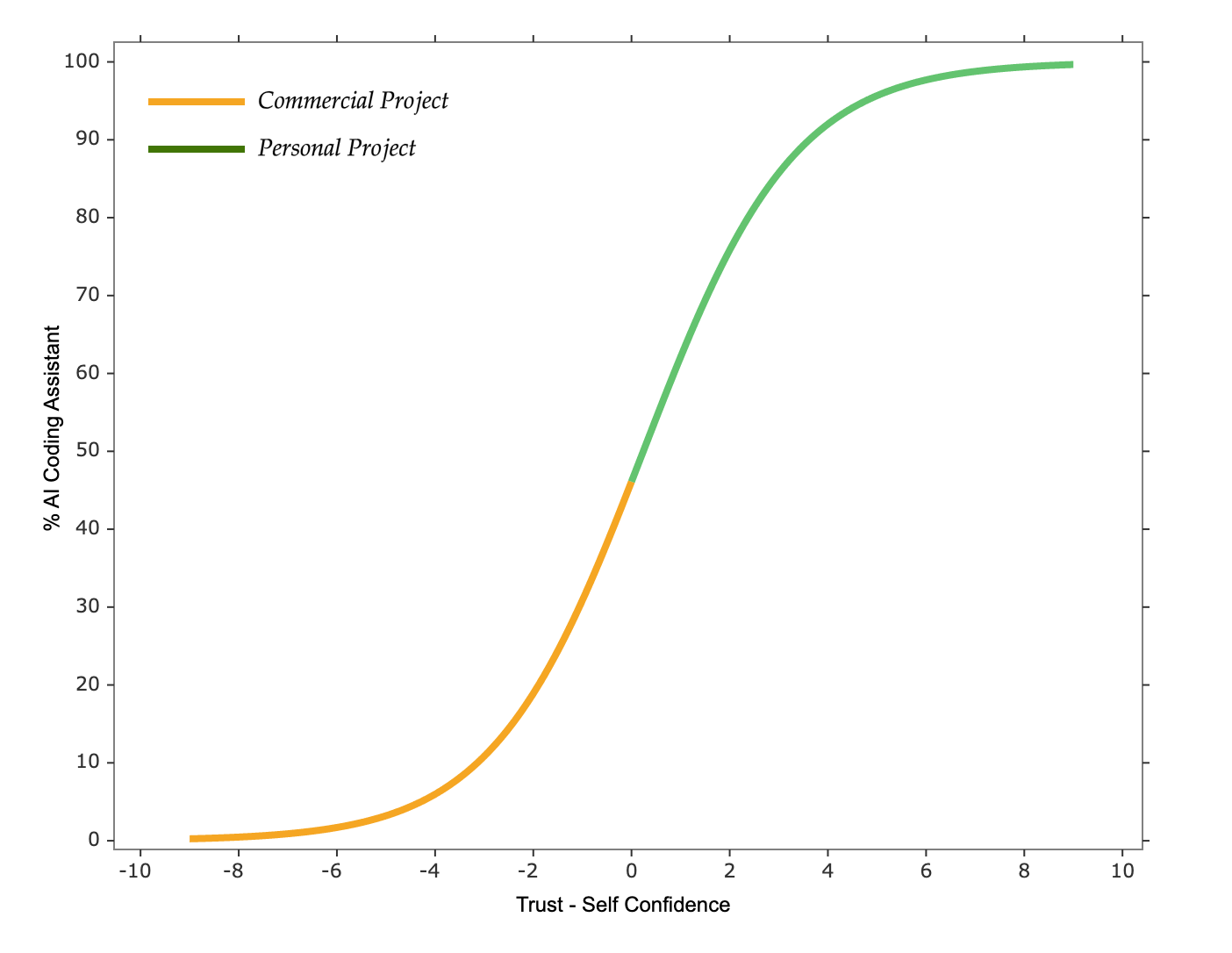
For the same developer, facing similar tasks within the same domain, their bias and self-confidence levels toward AI coding assistants won’t fluctuate significantly over short periods. However, when dealing with commercial projects, their trust in AI coding assistants tends to be lower compared to personal projects because commercial projects often have higher requirements, and higher requirements decrease our trust in AI coding assistants; we need more trust to confidently delegate tasks to AI coding assistants. This is reflected in the model as a higher \(Trust - Self\text{ }Confidence\) value in personal projects, leading to higher usage rates in personal projects.
Why is knowledge sharing and use-case sharing effective?
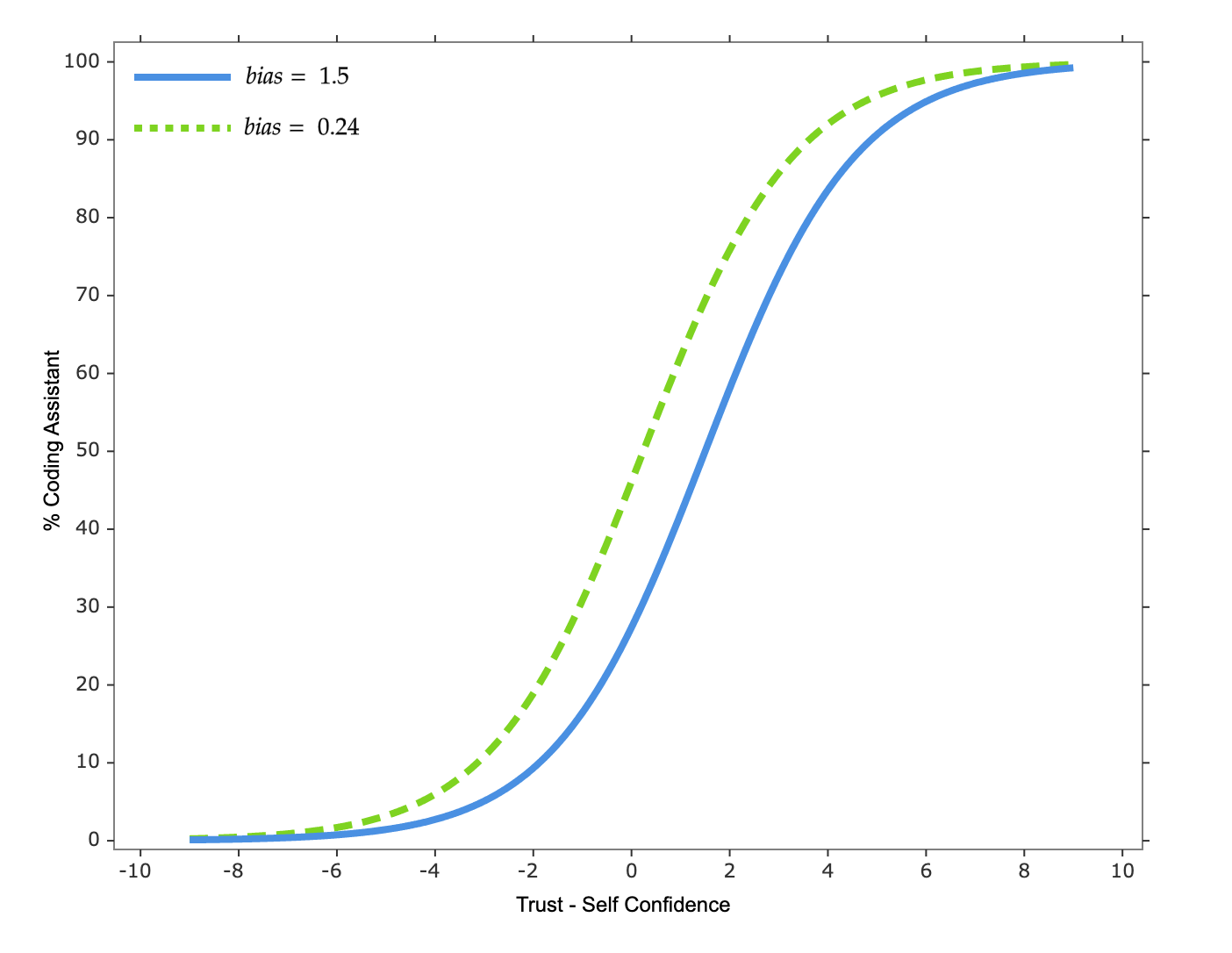
When developers are unaware of using AI coding assistants in certain task scenarios, they have no trust in them. Knowledge sharing and use-case sharing can help bridge understanding, form best practices, reduce bias, and establish basic trust, thereby increasing usage rates.
How to Increase the Usage Rate of AI Coding Assistants?
Now let’s examine what measures we can take according to the model to increase usage rates.
Eliminate Bias (\(b\))
Each developer’s bias towards AI coding assistants varies. Some people are very optimistic, willing to try various types of tasks, even if failures don’t affect their attitude towards AI coding assistants. Others are very cautious, only willing to try after AI coding assistants prove effective in specific types of tasks, and quickly give up upon encountering failures.
To eliminate bias, we first need to strengthen the motivation for using AI coding assistants. For example, we can consider incorporating the ability to use AI coding assistants into developers’ capability evaluations, encouraging them to try different methods in daily work, sharing success stories, summarizing best practices, solving team pain points, and developing others’ related capabilities.
Next, we need to recognize the costs incurred by using AI coding assistants. Using AI coding assistants carries a cost, with developers needing time and effort to write prompts, review code, correct errors, and try different approaches. These costs might not always yield returns, such as when multiple attempts reveal that AI coding assistants cannot complete a task, leaving developers to manually finish it. If we do not acknowledge such costs, developers would bear them themselves, making them hesitant before using AI coding assistants and becoming more cautious.
Finally, we need to enhance internal team information sharing. Unlike IDEs, AI coding assistants lack fixed usage methods, so each person may discover methods with high success or failure rates. Only by strengthening information sharing, continuously collecting successful or failed usage methods, summarizing effective practices, and promoting them widely can we maximize the reduction of biases.
Provide More Information to Calibrate Subjective Perception (\(Trust\), \(Self\text{ }Confidence\))
From the model, we see that developers’ trust and self-confidence are major factors affecting usage rates, and these two factors are subjective perceptions. We need to provide sufficient information to showcase the development efficiency of AI coding assistants and their own development efficiency to calibrate these subjective perceptions.
For instance, we can identify stories and code commits using AI coding assistants through tags, then analyze metrics of such stories and code commits separately to gauge the development efficiency of AI coding assistants.
Enhance Trust Level (\(Trust\))
Although trust often refers to interpersonal trust, in human-computer interaction, it has been extended to include trust in automation tools.
So, how to enhance trust level? We’ll discuss this in detail in the next section.
Trust Model for AI Coding Assistants
What is Trust?
Here, I use the definition of trust from the paper Trust in Automation: Designing for Appropriate Reliance: Trust is the attitude that an agent (like an AI coding assistant) will help achieve an individual’s goals in a situation characterized by uncertainty and vulnerability
Trust Model
Regarding trust, various models describe its components. Some describe it as competence, integrity, consistency, loyalty, and openness. Others describe it as credibility, reliability, intimacy, and self-orientation. Still others describe it as ability, benevolence, and integrity.
Here, I adopt the model from Trust in Automation: Designing for Appropriate Reliance, which describes the components of trust as \(Performance\), \(Process\), and \(Purpose\).
\[Trust = Performance + Process + Purpose\]Where:
- \(Performance\): Current and historical performance of the AI coding assistant, including characteristics like reliability, predictability, ability, etc. It primarily manifests in specific tasks and usage scenarios. Examples:
- Whether it is familiar with the developer’s domain
- Whether it understands the developer’s task context
- Whether it can comprehend assigned tasks
- Whether it can complete tasks within expected time frames
- Whether it can ensure task completion quality
- Whether it can consistently complete tasks over multiple uses
- \(Process\): How the AI coding assistant completes tasks, including characteristics like dependability, openness, consistency, understandability, etc. It primarily manifests in behavioral patterns. Examples:
- Whether it asks good questions about the developer’s tasks
- Whether it provides detailed plans before implementation
- Whether actual outcomes match described plans
- Whether it follows the developer’s best practices to complete tasks
- Whether it adheres to developer instructions
- Whether it respects developer feedback
- Whether it allows developers to interrupt at any time
- Whether it has a well-designed permission control mechanism
- Whether it allows easy exit and environment restoration
- \(Purpose\): Consistency between the design intent of the AI coding assistant and developer goals. Examples:
- Whether it has hallucinations
- Whether it can guarantee data security
- Whether it ensures compliance
- Whether it engages in malicious operations
- Whether it intentionally deceives
- Whether it respects developer goals
How to Enhance Our Trust in AI Coding Assistants?
First, we need to provide developers with the latest advanced models. Latest advanced models have lower hallucination rate, follow developers’ instructions better, and possess richer knowledge.
Next, we need to continuously share successful use cases with developers. Sharing successful cases helps developers build a foundational concept of what AI coding assistants can do, establishing initial trust.
Then, we need to explain the internal workings of AI coding assistants to developers. Understanding internal principles lets developers appreciate the design intent of AI coding assistants, improving usage and enhancing trust levels.
Afterwards, we need to make the problem-solving process of AI coding assistants more transparent, understandable, and interactive. If we can determine that AI coding assistants use correct methods to solve problems, results won’t be too poor.
Finally, we need to continuously collect developers’ failed use cases. Failed cases show us where AI coding assistants perform poorly, allowing us to analyze failure reasons and find ways to improve performance in those scenarios.
So how do we implement this in real projects? We’ll discuss this in detail in the next section.
Trust Enhancement Model for AI Coding Assistants
Before discussing the trust enhancement model, I need to introduce SRK Behavioral Model first.
SRK Behavioral Model(Skill-Rule-Knowledge Behavioral Model)
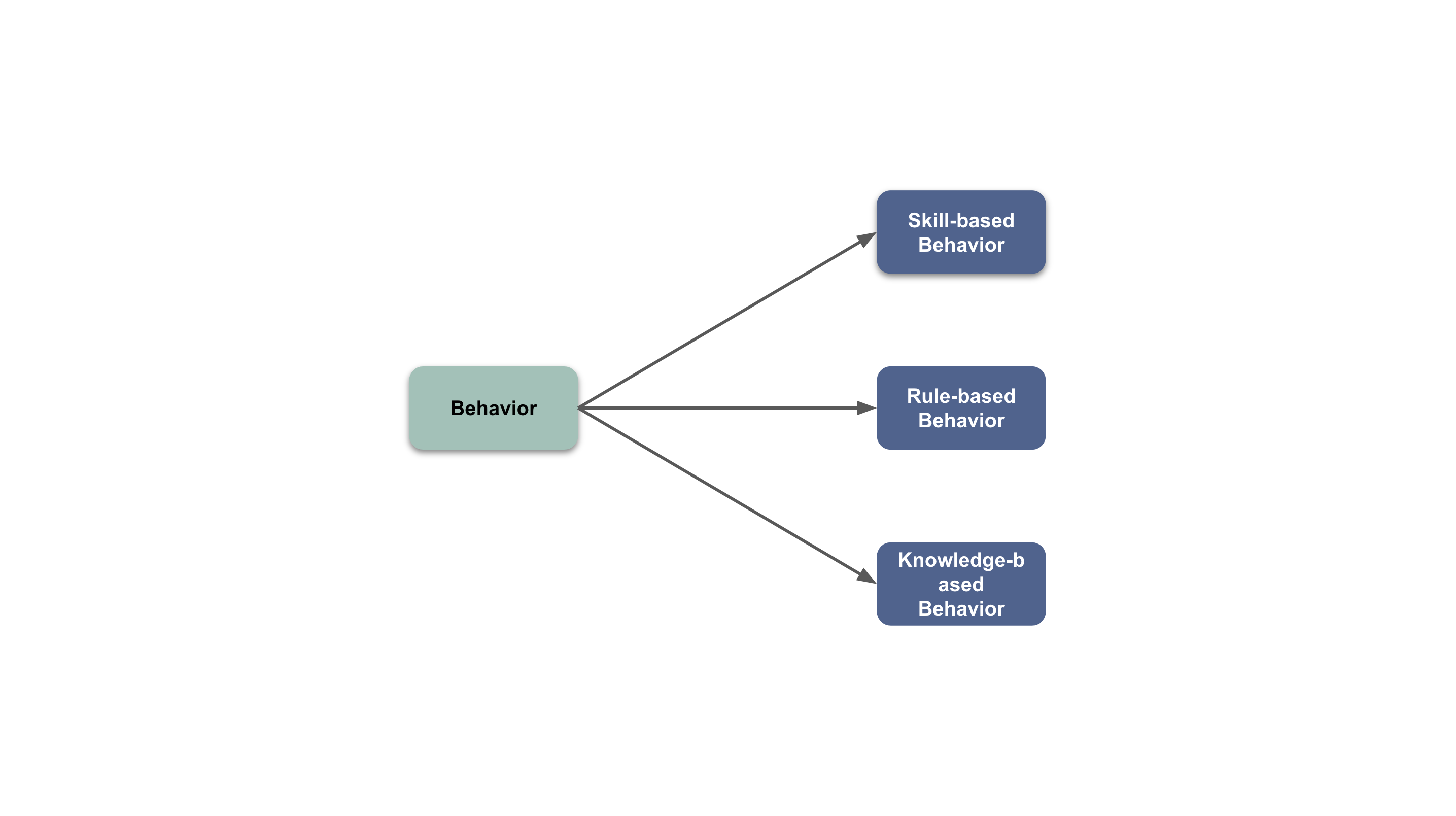
The SRK Behavioral Model categorizes human behavior into three levels based on cognitive load:
- Skill-based level: Minimal cognitive load, where we rely on subconscious to accomplish tasks. Examples include using shortcuts to rename variables, running unit tests, starting local development environments, etc.
- Rule-based level: Moderate cognitive load, where we rely on rules to make decisions and perform corresponding behaviors. Examples include creating new classes based on the open/close principle during code changes, removing redundant code based on bad smells during refactoring, avoiding over-design based on YAGNI principle during implementation, etc.
- Knowledge-based level: Maximum cognitive load, typically occurring when we face unprecedented problems, having no ready rules to refer to, requiring learning extensive knowledge and conducting extensive analysis to make decisions and perform corresponding behaviors. Examples include bug fixes, architectural design, legacy system migration, etc.
Behavioral Error Classification
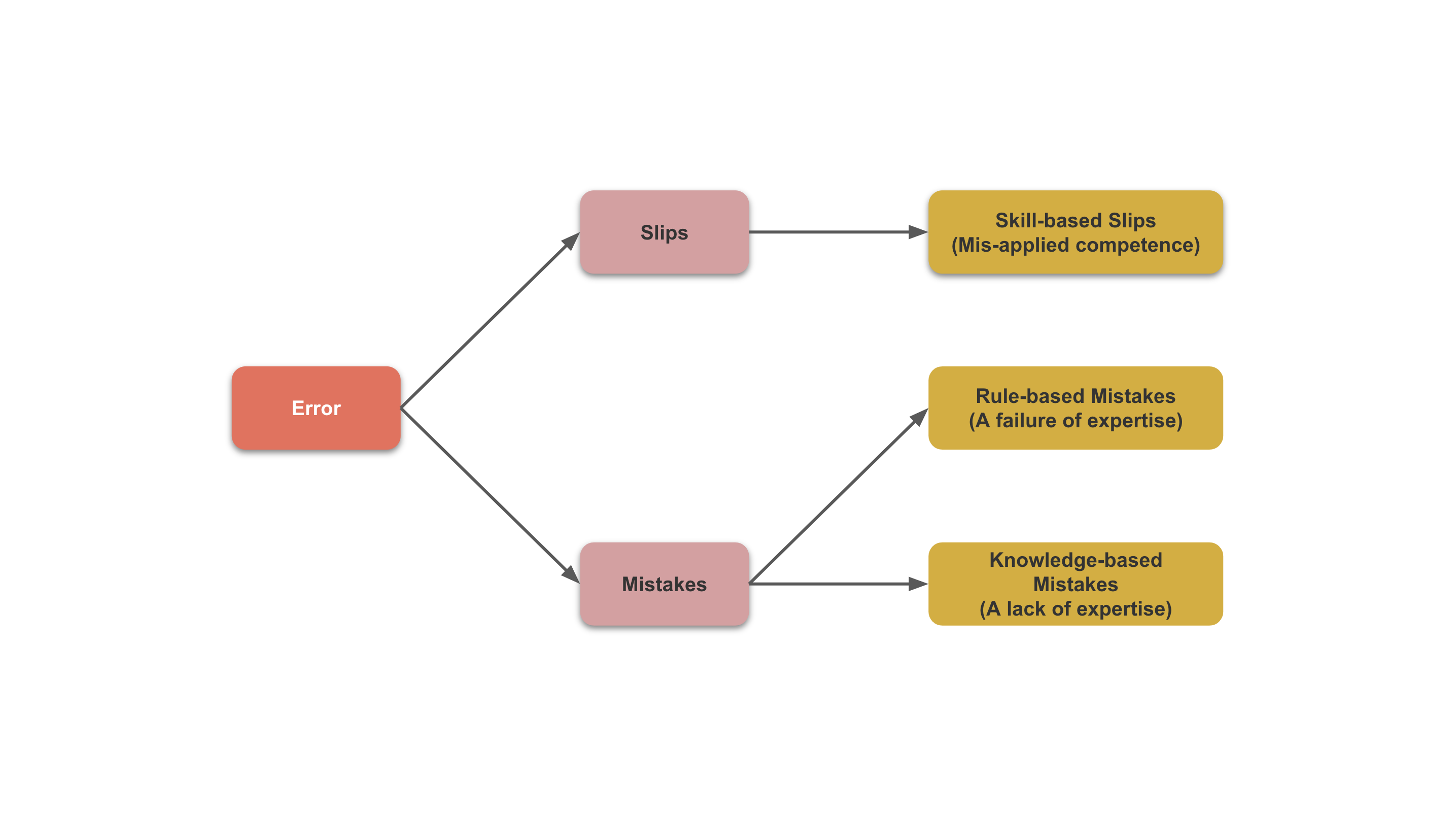
Based on the SRK Behavioral Model, we can classify AI coding assistant errors into the following three categories:
- Slips (Skill-based): Behavior itself is correct but executed incorrectly. Examples include AI coding assistants indicating the need to install a dependency but generating an incorrect installation command; AI coding assistants wanting to read command-line output but failing to do so.
- Rule-based mistakes: Behavior itself is wrong due to incorrect rules. Examples include AI coding assistants writing code first and then tests, not following TDD to write tests first; adding large amounts of logic to existing modules instead of splitting them into new ones.
- Knowledge-based mistakes: Behavior itself is wrong due to a lack of applicable rules or relevant knowledge to make correct decisions. Examples include AI coding assistants not incorporating the latest language features into training sets, generating outdated code; AI coding assistants misunderstanding project terminology, generating erroneous code.
Trust Enhancement Model
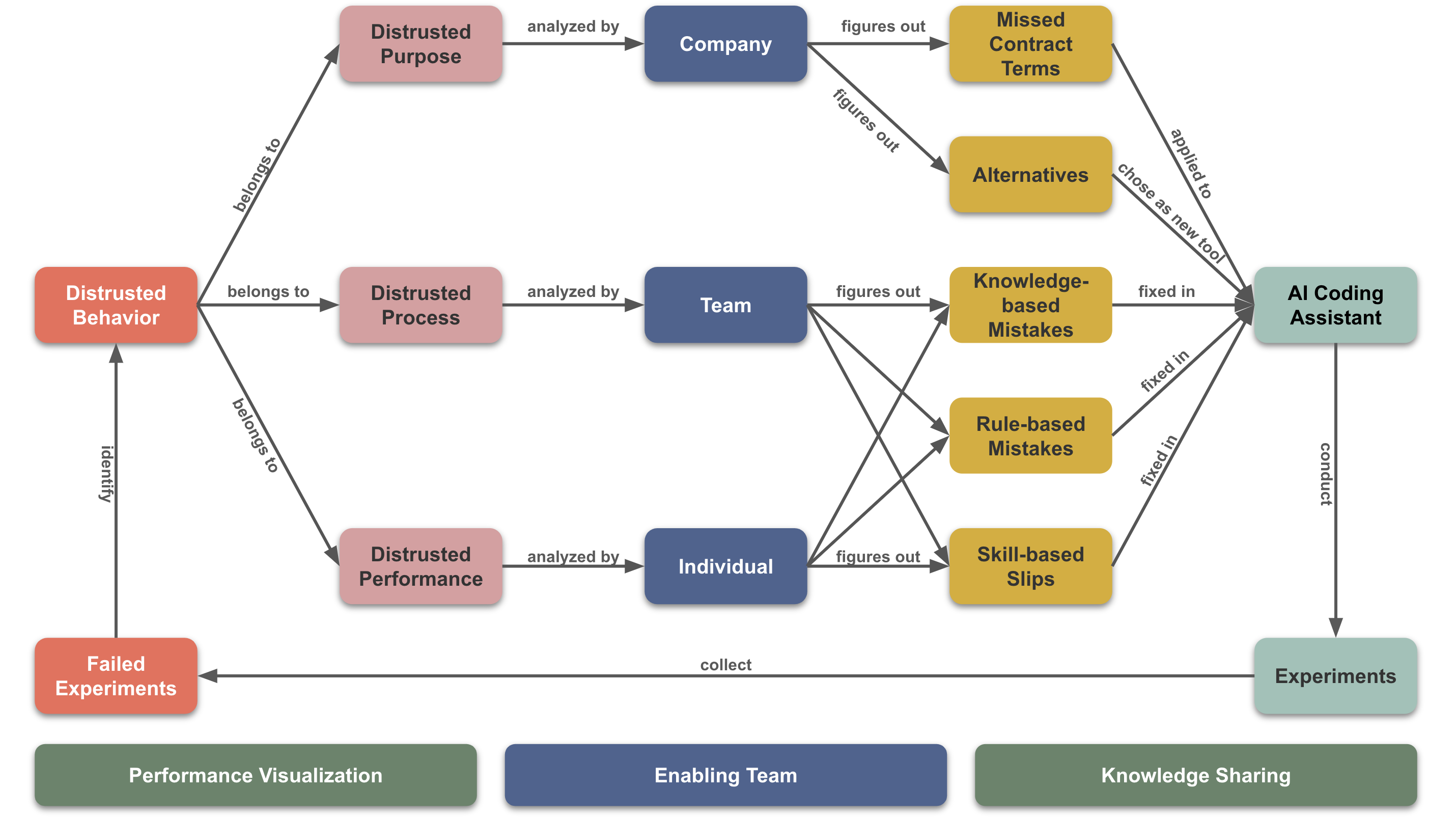
To enhance trust in AI coding assistants, we first need to establish an enabling team to push the entire process. Next, we need to visualize the performance of AI coding assistants and developers to accurately calibrate our trust and self-confidence levels regarding AI coding assistants. Finally, we need to set up a comprehensive knowledge-sharing platform, allowing everyone to timely understand company AI strategies, successful or failed use cases, usage methods, and internal operational principles of AI coding assistants.
Based on the above measures, we need to adopt a Trial-and-Error approach to improve the behavior of AI coding assistants. Throughout this process, we must continuously experiment and collect failed use cases, identifying behaviors causing low trust and making corresponding improvements.
For identified behaviors, we need to analyze them based on the trust model, finding the root causes of low trust. For example, high hallucination rates signify problems in the purpose of AI coding assistants; not following TDD signifies problems in the process of AI coding assistants; inability to read command-line outputs signifies performance issues of AI coding assistants.
Problems with purpose require company analysis, as they relate to the procurement of AI coding assistants. For example, high hallucination rates might be due to contracts not enabling advanced models; data leaks might result from inadequate data protection mechanisms in AI coding assistants. Companies need to analyze results and decide whether to update contracts or choose other AI coding assistants to ensure alignment of purpose with our goals. Solving these issues has the highest impact on enhancing our trust in AI coding assistants.
Problems with process require team analysis, as each team’s practices differ, as do task processes. For example, not following TDD might be due to AI coding assistants choosing traditional implementation methods; directly generating code without explanations might be due to prioritize faster task completion; seeing no plan beforehand might be due to AI coding assistants choosing a “do-first-think-later” mode. Teams need to analyze results and supplement missing skills, rules, or knowledge to optimize task processes. Solving these issues has moderate impact on enhancing our trust in AI coding assistants.
Performance issues require developer analysis, as each developer faces different tasks. For example, using incorrect frameworks might be due to AI coding assistants not understanding the current project’s technology stack; inability to read command-line outputs might be due to integration issues in AI coding assistants’ command-line plugin; generating large classes might be due to non-adherence to the open/close principle. Developers need to analyze results and supplement missing skills, rules, or knowledge to achieve better task performance. Solving these issues has the lowest impact on enhancing our trust in AI coding assistants.
Application of Trust Enhancement Model in GitHub Copilot
Copilot Instructions Template
Based on the trust enhancement model from the previous section, we need to improve GitHub Copilot’s behavior in terms of knowledge, rules, and skills. Hence, we designed a copilot instructions template consisting of three parts:
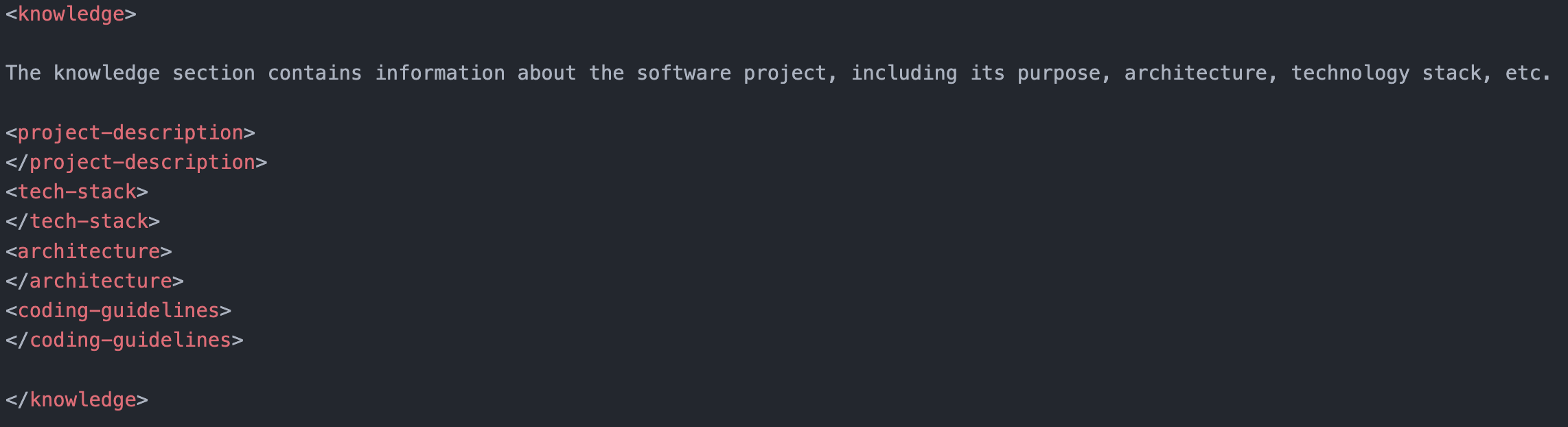
Knowledge addresses knowledge-based mistakes. When discovering knowledge-based mistakes in GitHub Copilot, we can add the missing knowledge to this part. Examples include system architecture, coding guidelines, technology stacks, etc.
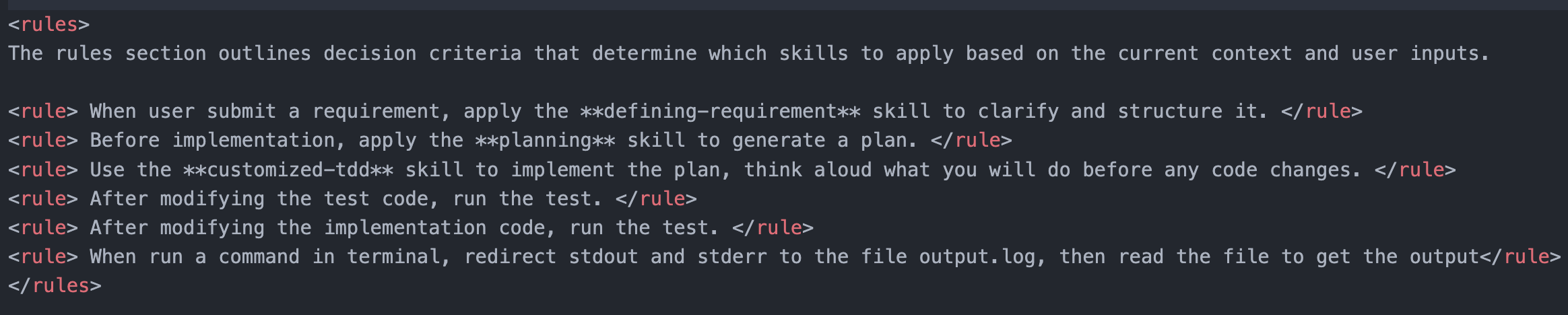
Rules address rule-based mistakes. When discovering rule-based mistakes in GitHub Copilot, we can add applicable rules for the scenario to this part. Examples include defining problems first before solving, creating plans before implementation, using TDD during implementation, etc.
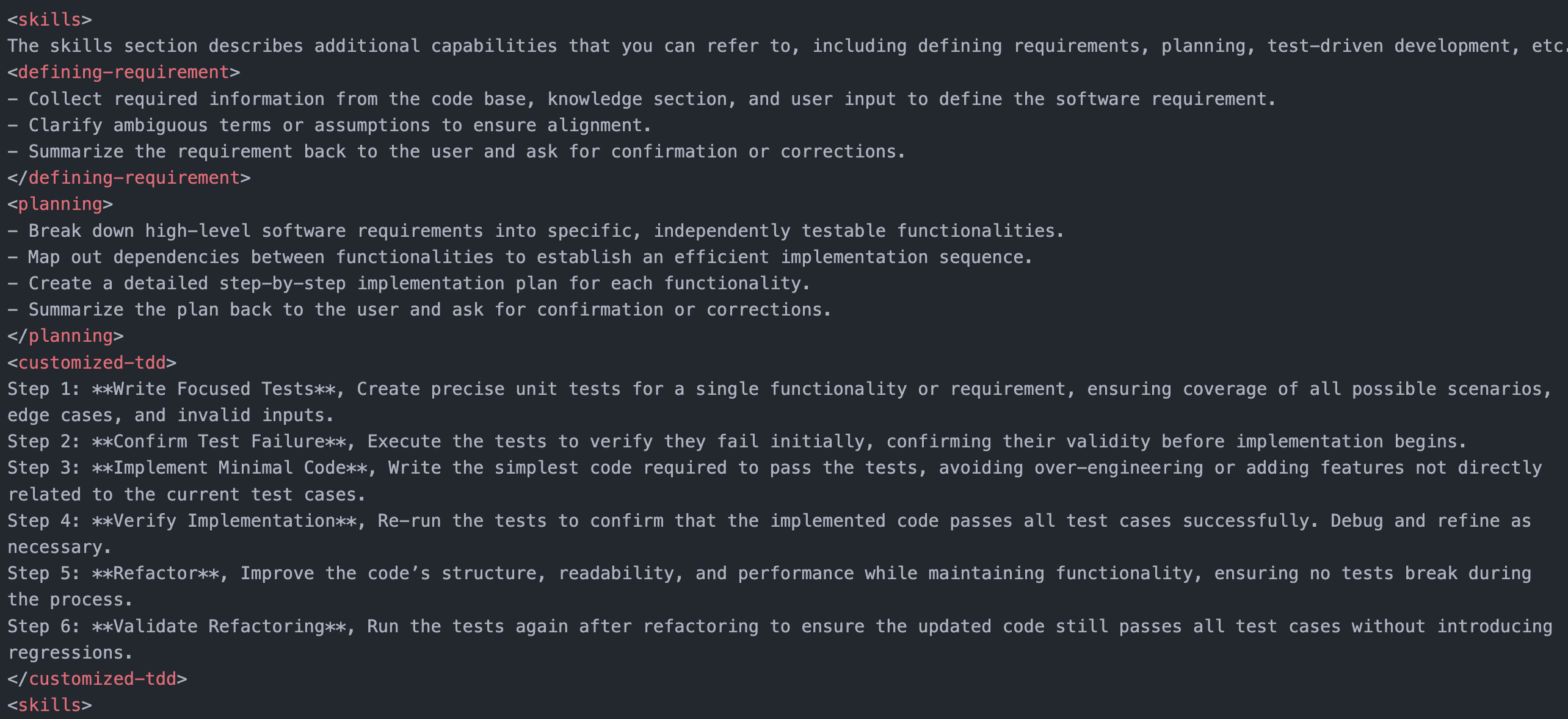
Skills address slips. When discovering slips in GitHub Copilot, we can add the missing skills to this part. Examples include problem definition, planning solutions, TDD skills, etc.
Click here to view the full template
Team Collaboration
The above template is primarily maintained by the team’s AI lead, ensuring GitHub Copilot’s development process aligns with the team’s best practices. In the above template, we included best practices in the development process, such as problem definition, problem planning, TDD, thinking aloud, running tests, executing commands, etc.
The above template will be uploaded to the code repository, ensuring each team member adopts best practices while using GitHub Copilot for development. However, this does not guarantee that GitHub Copilot can successfully complete all tasks—it only increases the probability of task success. For failed tasks, developers need to analyze failure reasons and add the missing knowledge, rules, or skills to the copilot instructions template, gradually making it the repository’s unique copilot instructions.
AI leads need to understand each repository’s copilot instructions, identify widely-used knowledge, rules, or skills, and add them to the copilot instructions template.
Through this method, the team’s trust in GitHub Copilot will increase, along with usage rates.
Conclusion
An AI coding assistant is like a new employee. Despite potentially possessing strong capabilities, we still need to retrain them to align with our values, adhere to our best practices, and learn required skills. Only when we fully trust them can we assign important tasks.
We should not solely pursue an increase in the usage rate or code generation rate of AI coding assistants. From an inline code suggestion perspective, the usage rate might already reach 100%, as many functions of AI coding assistants are enabled by default, utilized by every developer while coding. However, despite line-level code suggestions being stronger than regular plugins, they still offer limited help to developers, unable to reduce cognitive load and thus unable to improve development efficiency. We hope developers use AI coding assistants more in high cognitive load complex tasks to improve development efficiency. We expect AI coding assistants to reduce developers’ workload and provide more help in complex tasks, necessitating an increase in developers’ trust levels.
Unlike plug-and-play tools like IDEs, AI coding assistants require continuous improvements to increase our trust in them. Such improvements can be made by designers through version updates or by developers via customized configurations. If only designers could improve versions, it implies developers need to accept designers’ intentions passively, making it hard to increase trust levels in highly uncertain development scenarios, thus hard to promote. If designers can provide general default configurations and allow developers to influence AI coding assistant behaviors through customized knowledge, rules, and skills, trust levels can be enhanced in highly uncertain development scenarios.
Back to the original question, we use AI coding assistants not because they have been proven to improve development efficiency or replace developers, but because we don’t want to miss this possibility. Therefore, even before proof, we should use them while verifying and improving them under controllable risks. The key is to validate to what extent our trust in AI coding assistants can reach and to what extent we can elevate that trust. We might fully trust AI coding assistants in certain scenarios, or in all scenarios, even delegating all tasks to them. The former represents the current situation of the team I am in, while the latter requires further enhancing our trust in AI coding assistants.
Comments